Architecture
Architecture explains how Joulie’s per-node digital twins turn telemetry into enforcement decisions.
If you are new, first read:
Core story
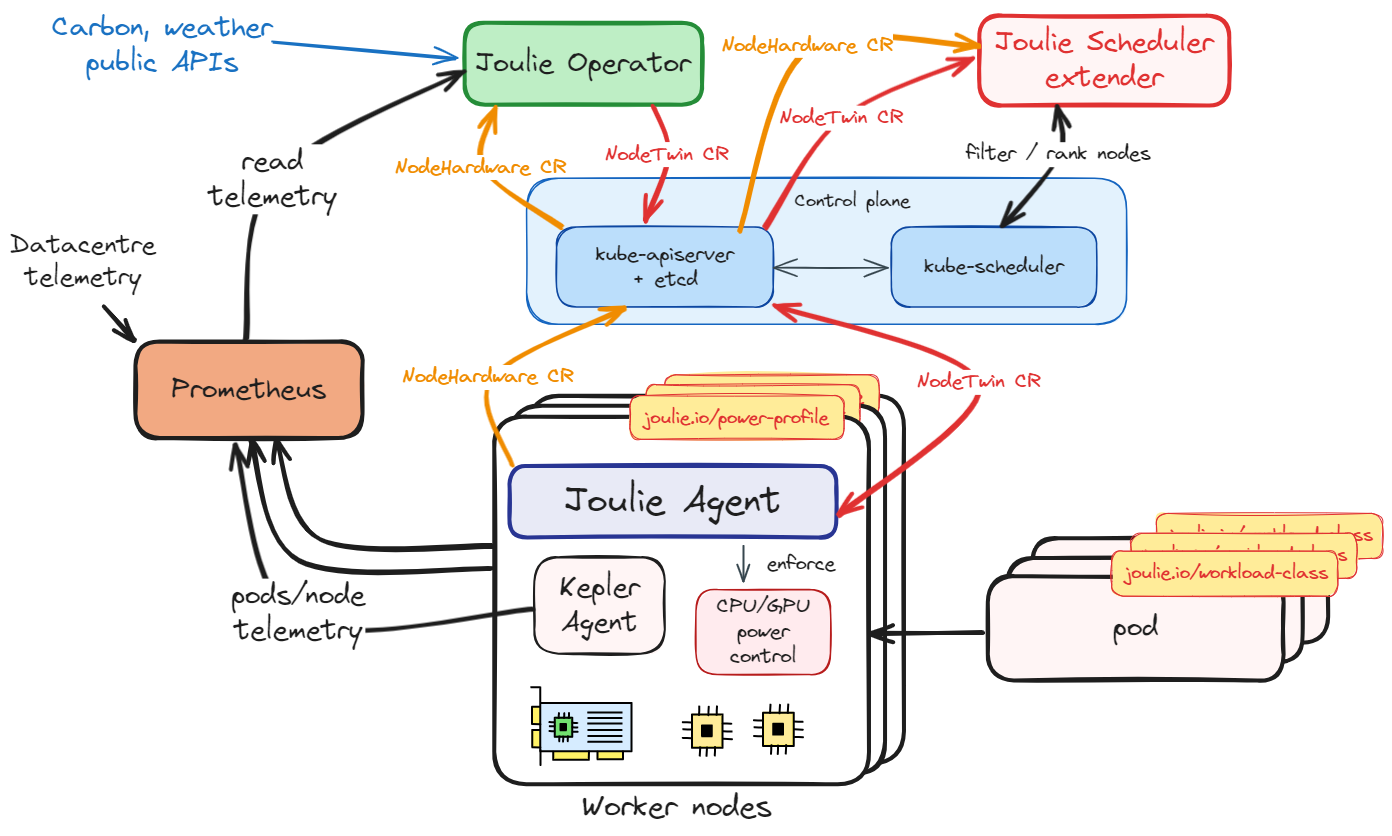
- Agent discovers node hardware (CPU/GPU models, cap ranges, frequency landmarks, GPU slicing modes) and publishes a single
NodeHardwareCR per node. - Operator twin controller ingests
NodeHardware+ Prometheus telemetry, runs the digital twin model, and writesNodeTwin.statusper node (headroom, cooling stress, PSU stress). - Operator policy controller reads
NodeTwin.status+ demand signals, runs a policy algorithm, writesNodeTwin.specand node supply labels (joulie.io/power-profile). Transition state is tracked internally viaNodeTwin.status.schedulableClass. - Agent reads
NodeTwin.specand enforces power caps via RAPL (CPU) and NVML (GPU). Writes control feedback toNodeTwin.status.controlStatus. - Scheduler extender reads
NodeTwin.statusand filters/scores nodes at pod scheduling time based on power profile, facility stress, and workload class. - Telemetry and status feed the next reconcile step, closing the loop.
Key CRDs
| CRD | Owner | Purpose |
|---|---|---|
NodeHardware | Agent | Hardware facts: CPU/GPU model, cap ranges, frequency landmarks, GPU slicing modes |
NodeTwin | Operator | Desired state (spec: power cap %) + twin output (status: headroom, cooling stress, PSU stress, migration recommendations, GPU slicing recommendations, control feedback) |
The operator also manages WorkloadProfile CRs internally (per-pod workload classification). These are created automatically by the classifier and consumed by the twin. Users do not need to create or manage them.
Component roles
Operator
The operator contains three reconcile-loop controllers and three background controllers:
Reconcile-loop controllers (run each tick):
- Twin controller: ingests per-node telemetry into
NodeTwin.status. Runs theCoolingModeland PSU stress computations. Incorporates facility metrics (ambient temperature, PUE) when available. When nodes carryjoulie.io/rackorjoulie.io/cooling-zonelabels, the twin computes PSU stress per-rack and cooling stress with per-zone ambient temperature. - Policy controller: reads
NodeTwin.status+ pod demand signals, runs the policy algorithm (pkg/operator/policy/), writesNodeTwin.specand thejoulie.io/power-profilenode label. The state machine (pkg/operator/fsm/) enforces downgrade guards: nodes cannot transition from performance to eco while performance-sensitive pods are still running. Transition state is tracked viaNodeTwin.status.schedulableClass. - Migration controller: evaluates node stress levels and workload migratability (
pkg/operator/migration/). When CoolingStress or PSUStress exceeds thresholds, generates reschedule recommendations for reschedulable standard workloads.
Background controllers (run on independent intervals):
- Workload classifier (
ENABLE_CLASSIFIER=trueby default): watches running pods, queries Prometheus/Kepler metrics, and writesWorkloadProfileCRs. Two-phase classification: static hints from annotations, then dynamic metrics. In simulator mode, the classifier can fall back tosim.joulie.io/*pod annotations when Prometheus is unavailable (CLASSIFY_SIM_ANNOTATION_FALLBACK=true). - Facility metrics poller (
ENABLE_FACILITY_METRICS=falseby default): queries Prometheus for ambient temperature, IT power, and cooling power. Computes PUE for twin and scheduler consumption. - Active rescheduler (
ENABLE_ACTIVE_RESCHEDULING=falseby default): readsNodeTwin.status.rescheduleRecommendationsand evicts misplaced pods via the Kubernetes Eviction API. Only affects pods with thejoulie.io/reschedulable=trueannotation. Before eviction, annotates the pod’s owner with eviction context so the scheduler avoids re-placing the replacement pod in the same situation.
Agent
The agent is the node-side enforcement component.
It discovers local hardware, publishes NodeHardware, reads NodeTwin.spec, and applies CPU and GPU controls through configured backends (RAPL for CPU, NVML for GPU). Control feedback is written to NodeTwin.status.controlStatus.
Scheduler extender
The scheduler extender is a read-only HTTP service that participates in the Kubernetes scheduling cycle.
- Filter: rejects eco nodes for performance pods and for pods whose owner was recently evicted from eco (hard rule).
- Score: ranks nodes using
score = headroom*0.4 + (100-coolingStress)*0.3 + (100-psuStress)*0.3, with workload-class adjustments, marginal power estimation, and eviction history penalties.
kubectl plugin
The kubectl joulie plugin (cmd/kubectl-joulie) provides immediate visibility into the cluster’s energy state:
kubectl joulie status: per-node overview of power profiles, cap settings, twin stress scores.kubectl joulie status --explain: adds a workload classification table showing each WorkloadProfile’s class, confidence, CPU/GPU boundness, and classification reason.kubectl joulie recommend: GPU slicing and reschedule recommendations fromNodeTwin.status.
No configuration is needed. The plugin reads your current kubeconfig context.
Digital twin model
The pkg/operator/twin package implements an O(1) parametric model computing:
- Power headroom: remaining capacity before hitting the configured cap
- Cooling stress (0-100): predicted % of cooling capacity in use. High means risk of thermal throttling.
- PSU stress (0-100): predicted % of PDU/rack power capacity in use. High means risk of power brownout.
The CoolingModel interface is pluggable. Default: LinearCoolingModel (algebraic proxy). Future: openModelica reduced-order thermal simulation via the same interface.
Read in this order
- CRD and Policy Model
- Joulie Operator
- Joulie Agent
- Digital Twin
- Scheduler Extender
- Workload Classification
- Energy-Aware Scheduling
- GPU Slicing Recommendations
- Policy Algorithms
- Input Telemetry and Actuation Interfaces
- Hardware Modeling and Physical Power Model
- Metrics Reference
Workload Classification
How Joulie’s classifier combines static hints and dynamic metrics to produce WorkloadProfile CRs that drive scheduling and twin decisions.
Energy-Aware Scheduling
How Joulie combines Kepler telemetry, workload classification, digital twin predictions, and PUE-weighted scoring to make energy-aware scheduling decisions.