CPU-Only Benchmark
This page reports results from the CPU-only cluster benchmark experiment:
Scope
The benchmark compares three baselines on a pure CPU cluster:
A: simulator only (Joulie-free)B: Joulie with static partition policyC: Joulie with queue-aware policy
It evaluates energy and throughput under real Kubernetes scheduling with KWOK nodes and simulated power control.
Experimental setup
Cluster and nodes
- kind control-plane + worker (real control plane)
- 8 managed KWOK nodes - CPU only, no GPUs
- Workload pods target KWOK nodes via selector + toleration
Node inventory
| Node prefix | Count | CPU model | CPU cores | RAM |
|---|---|---|---|---|
| kwok-cpu-highcore | 2 | AMD EPYC 9965 192-Core | 384 (2×192) | 1536 GiB |
| kwok-cpu-highfreq | 2 | AMD EPYC 9375F 32-Core | 64 (2×32) | 770 GiB |
| kwok-cpu-intensive | 4 | AMD EPYC 9655 96-Core | 192 (2×96) | 1536 GiB |
Total: 8 nodes, 2304 CPU cores, 0 GPUs.
Hardware models in simulator
CPU power per node:
P(u, f) = IdleW + (PeakW - IdleW) * u^AlphaUtil * f^BetaFreq
| CPU family | IdleW (W) | PeakW (W) | AlphaUtil | BetaFreq |
|---|---|---|---|---|
| AMD EPYC 9965 192-Core | 120 | 960 | 1.15 | 1.30 |
| AMD EPYC 9375F 32-Core | 60 | 480 | 1.10 | 1.25 |
| AMD EPYC 9655 96-Core | 95 | 760 | 1.12 | 1.28 |
Full power-model details: Power Simulator
Run configuration
- Seeds:
3 - Mean inter-arrival:
0.12 s - Time scale:
60× - Timeout:
14400 s - Perf ratio:
15%, eco ratio:0%, GPU ratio:0% - Workload types:
cpu_preprocess,cpu_analytics - Policy caps: CPU eco at
80%of peak
Algorithms used
Controller policies
static_partition:hpCount = round(N * 0.45)→ 4 performance nodes, 4 eco nodes
queue_aware_v1:baseCount = round(N * 0.50), dynamic from live perf-pod counthpCount = clamp(max(baseCount, queueNeed), 2, 8, N)
- Downgrade guard:
performance → ecodeferred while performance-sensitive pods still run on node
Results summary
Primary metrics: summary.csv
Per-seed results
| Baseline | Seed | Wall (s) | Throughput (jobs/sim-hr) | Energy (kWh sim) | Avg power (W) |
|---|---|---|---|---|---|
| A | 1 | 1048.97 | 285.99 | 20.65 | 1181.1 |
| A | 2 | 1073.38 | 279.49 | 23.85 | 1333.2 |
| A | 3 | 1164.21 | 257.69 | 23.24 | 1197.6 |
| B | 1 | 1068.72 | 280.71 | 18.57 | 1042.8 |
| B | 2 | 1072.93 | 279.61 | 23.46 | 1312.1 |
| B | 3 | 1142.27 | 262.63 | 20.32 | 1067.5 |
| C | 1 | 1064.50 | 281.82 | 19.42 | 1094.6 |
| C | 2 | 1073.04 | 279.58 | 22.82 | 1276.2 |
| C | 3 | 1144.72 | 262.07 | 22.59 | 1183.8 |
Baseline means (3 seeds, all completed)
| Baseline | Mean wall (s) | Mean throughput (jobs/sim-hr) | Mean energy (kWh sim) | Mean cluster power (W) |
|---|---|---|---|---|
| A | 1095.5 | 274.39 | 22.58 | 1237.3 |
| B | 1094.6 | 274.32 | 20.79 | 1140.8 |
| C | 1094.1 | 274.49 | 21.61 | 1184.9 |
Relative to A:
- B: energy −7.9%, throughput ≈ 0% (negligible)
- C: energy −4.3%, throughput ≈ 0% (negligible)
Plot commentary
Runtime distribution
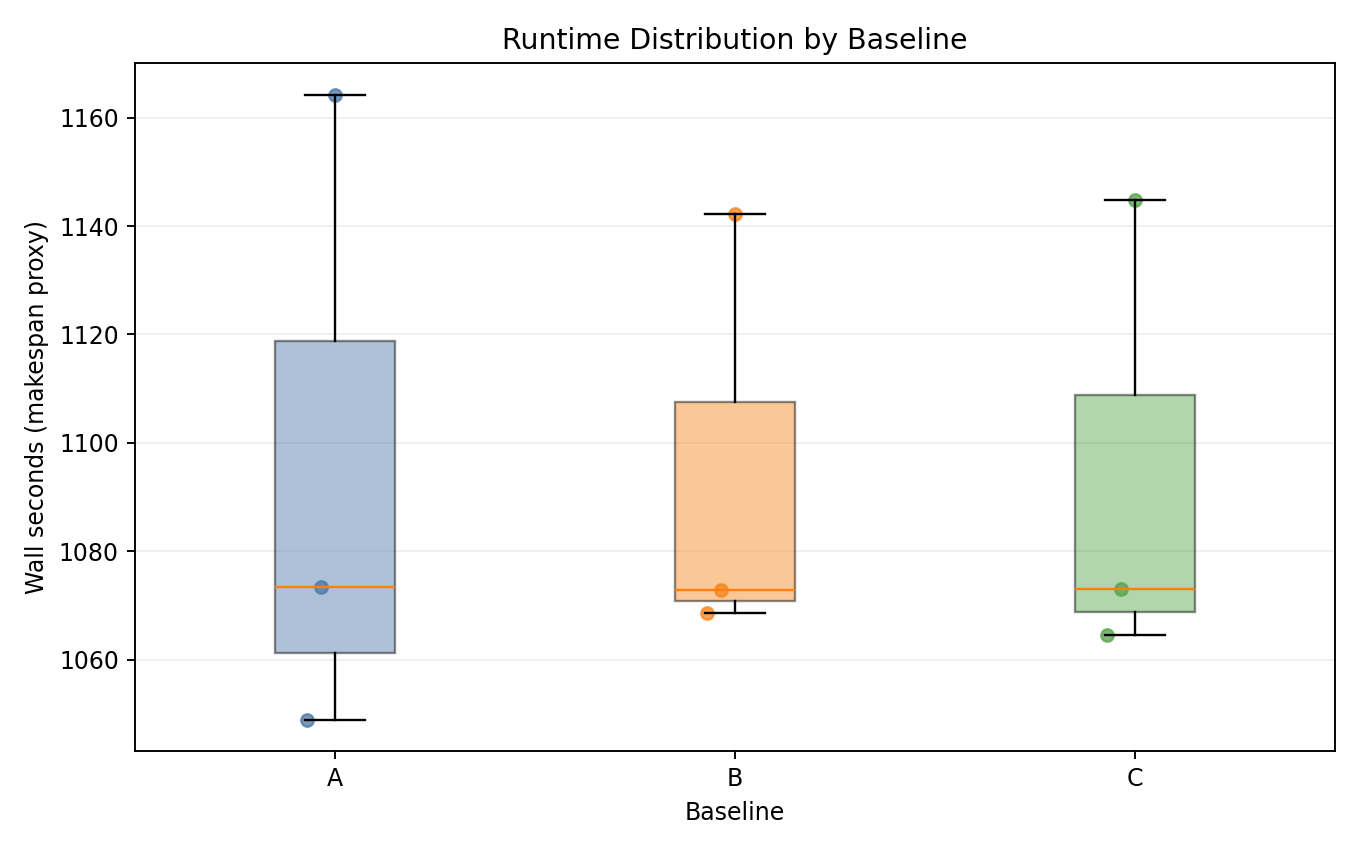
- All three baselines complete in nearly identical wall-time windows.
- Run-to-run seed jitter is larger than any inter-baseline difference.
Energy vs makespan
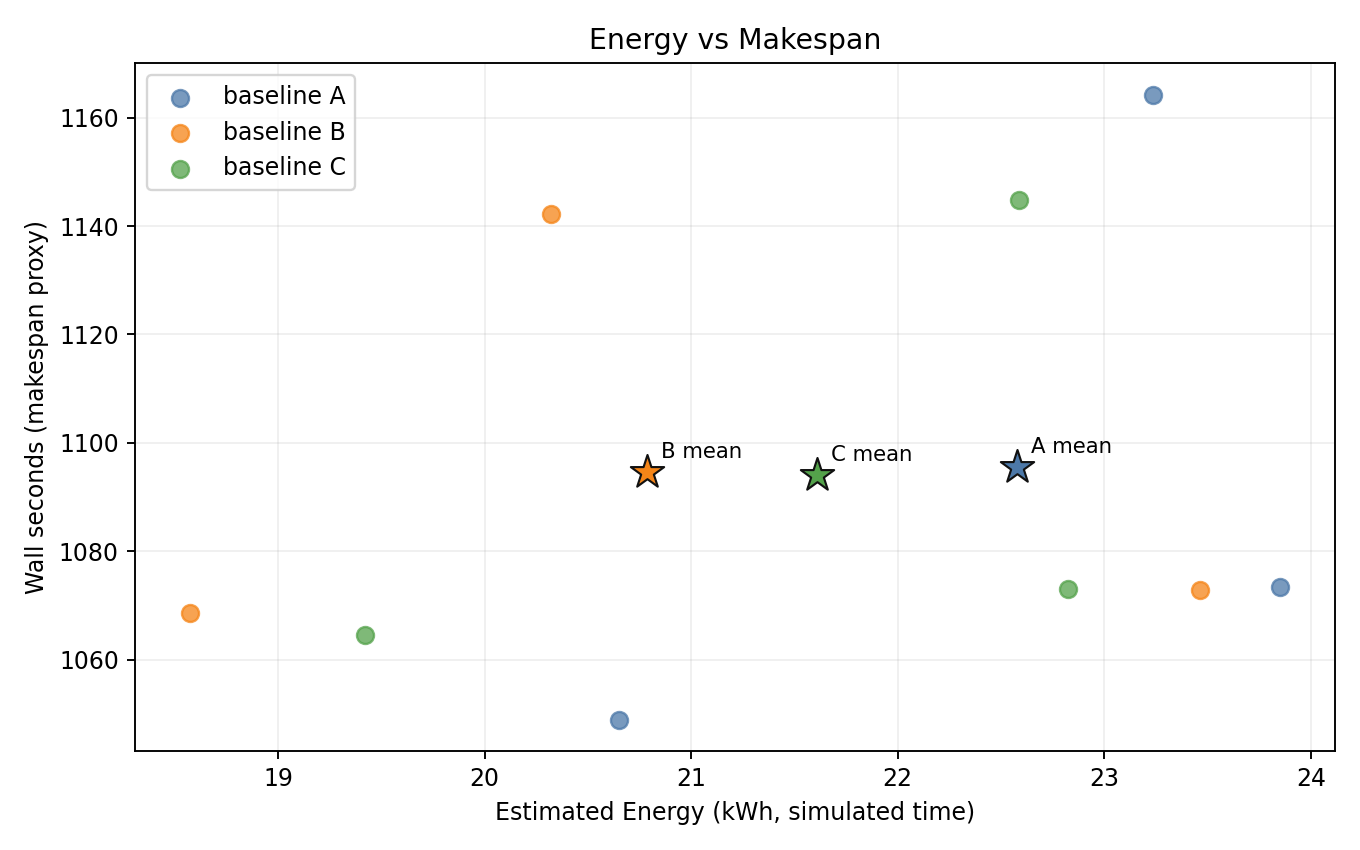
- B is consistently lower-energy than A with near-identical makespan across all 3 seeds.
- C shows slightly more variance; one seed lands close to A energy.
Baseline means
- Energy is the main differentiator; throughput and wall-time bars are indistinguishable.
Completion summary
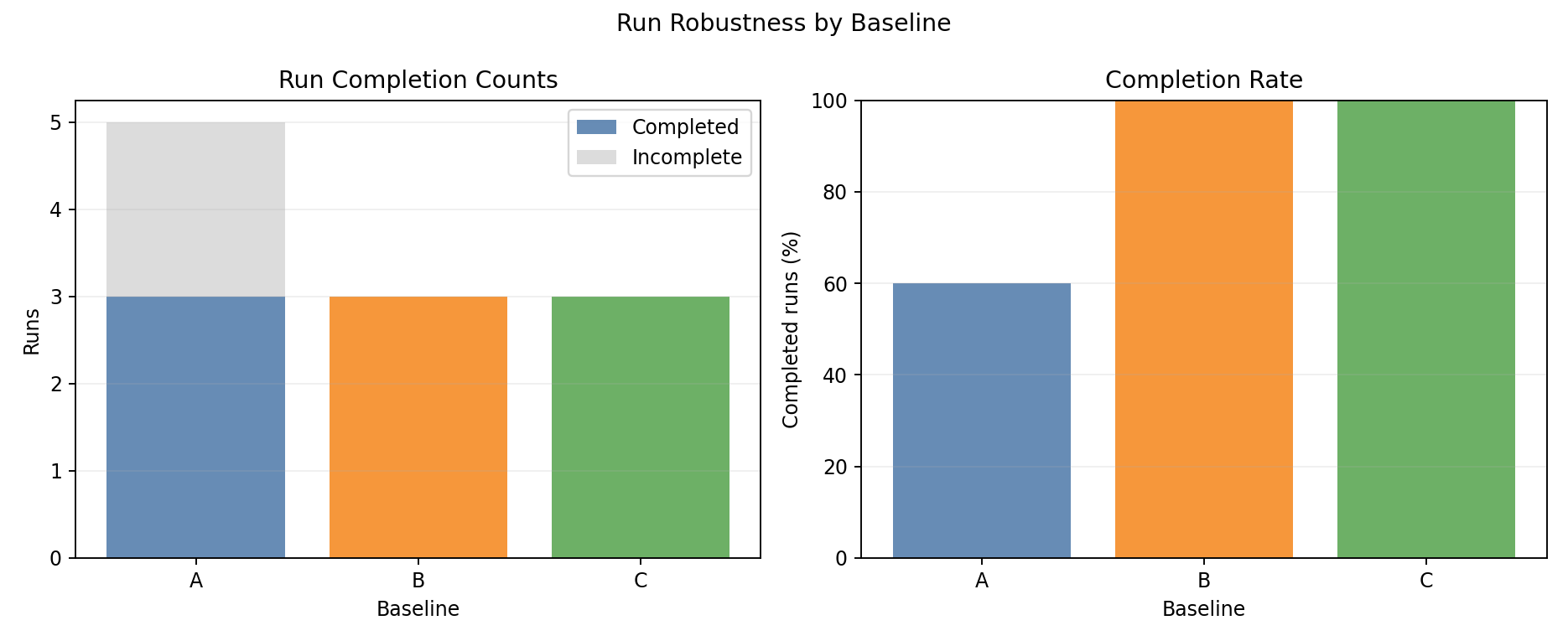
- All 3 seeds completed for all baselines; no timeouts or gang-scheduling issues.
Interpretation
Joulie reduces energy without throughput penalty on a CPU-only cluster because:
- The cluster is over-provisioned (2304 cores, lightweight jobs) - eco nodes have spare CPU cores to compensate for throttled frequency.
- CPU
sensitivityCPUforcpu_preprocess/cpu_analyticsis moderate (0.7–0.9): a 20% frequency reduction causes 14–18% per-job slowdown, but job completion time stays flat because the scheduler redistributes load. - Eco nodes draw proportionally less power for the same simulated duration → energy falls without extending makespan.
Best-fit use case
The strongest observed benefit is:
- energy reduction (−7.9% static, −4.3% queue-aware) with negligible throughput penalty in CPU-only mixed workload clusters.
static_partition is the most robust policy for this regime - predictable savings with no visible scheduling-performance impact.